In my group, we work with a lot of customers with very large EM environments. On the range of 2000+ agents. So as you can imagine there’s a little bit of optimizing that needs to get done to account for these numbers.
A few of these standard tweaks have been put into the repvfy execute optimize command. You can make all these changes individually, but if you want to get them all done at once, optimize is your tool.
There’s 3 categories of optimization that is handled at this point: Internal Tasks, Repository Settings and Target system. The script will first evaluate the size of your repository based on the number of agents, and from there determine what optimizations need to be done or recommended for future implementation.
Internal Task Tuning
Enterprise Manager uses short and long workers, depending on the task activity. We typically recommend 2 workers for each for most larger systems, so in repvfy execute optimize this is what gets set. Smaller systems are usually sufficient with the default settings of 1 each. You can view the configuration in EM on Manage Cloud Control -> Repository page. Here you can also configure the short workers, but not the long. If you see a high collection backlog, this is an indication that your in need of additional task workers.
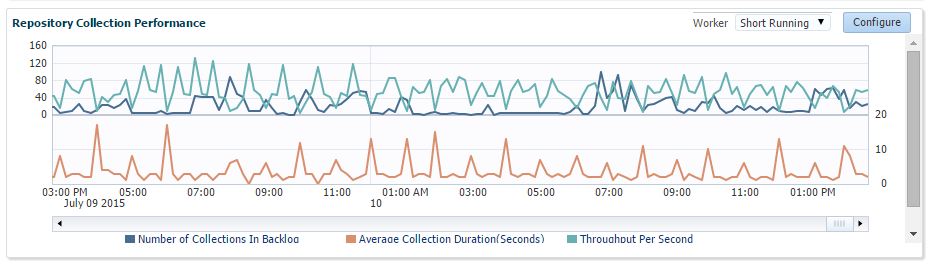
The next step is to evaluate the current settings of the job system and ensure that there are enough connections available for the job system. This change is not implemented automatically, but is printed out for you to change with emctl, as it will require a restart to take effect. Recommendations for Large Job System Load can be found in the Sizing chapter of Advanced Installation Guide. Increasing the number of connections may require an increase in database processes value.
Repository Settings Tuning
EM tracks system errors in one of it’s tables. In larger systems, the MGMT_SYSTEM_ERROR_LOG table can become quite large over the 31 day default retention. The optimize script reduces log retention to 7 days for normal operating.
There are also various levels of tracing enabled by default, this can generate a lot of extra activity during normal operations if you’re not utilizing the traces. Tracing is turned off by the optimize command. It can be enabled at any time by using the repvfy send start_trace -name <name> and repvfy send start_repotrace commands.
Finally this step looks for any invalid SYSMAN objects and validates them, then checks for stale optimizer statistics and makes a recommendation as needed.
System Tuning
After an EM outage or downtime, all the agents will attempt to upload and update their status (or heartbeat) with the OMS. There’s a grace period in which no alerts are sent. In larger systems, this grace period may not be long enough to get all agents updated before alerts start going out. This can be adjusted by increasing that grace period.
In 12.1.0.3 and higher, you can also increase the number of threads that perform the ping heartbeat tasks. This should be done if you have more than 2000 agents per OMS. The optimize command will make this calculation for you and recommend the appropriate emctl command to set the heartbeatPingRecorderThreads property. Recommendations for Large Number of Agents can be found in the Sizing chapter of Advanced Installation Guide.
The optimize command will only output those items that require attention, so not every item will appear in the output on every site.
The recommended values reported in the output are specific for THAT environment and should not be copied over to another environment just like that. To tune another EM environment, run the optimize script on that environment.
Sample output from a small EM system:
bash-4.1$ ./repvfy execute optimize
Please enter the SYSMAN password:
SQL*Plus: Release 11.1.0.7.0 – Production on Thu Jul 9 07:59:35 2015
Copyright (c) 1982, 2008, Oracle. All rights reserved.
SQL> Connected.
Session altered.
Session altered.
========== ========== ========== ========== ========== ========== ==========
== Internal task system tuning ==
========== ========== ========== ========== ========== ========== ==========
– Setting the number of short workers to 2 (1->2)
– Setting the number of long workers to 2 (1->2)
========== ========== ========== ========== ========== ========== ==========
========== ========== ========== ========== ========== ========== ==========
== Job system tuning ==
========== ========== ========== ========== ========== ========== ==========
– On each OMS, run this command:
$ emctl set property -name oracle.sysman.core.conn.maxConnForJobWorkers -value 72 -module emoms
This change will require a bounce of the OMS
========== ========== ========== ========== ========== ========== ==========
========== ========== ========== ========== ========== ========== ==========
== Repository tuning ==
========== ========== ========== ========== ========== ========== ==========
– Setting retention for MGMT_SYSTEM_ERROR_LOG table to 7 days (31->7)
– Disabling PL/SQL tracing for module (EM.GDS)
– Disabling PL/SQL tracing for module (EM_DBM)
– Disabling repository metric tracing for ID (1234)
– Recompiling invalid object (foo,TRIGGER)
– Recompiling invalid object (bar,CONSTRAINT)
– Stale CBO statistics in the repository. Gather statistics for the SYSMAN schema
Command to use:
$ repvfy send gather_stats
Or:
SQL> exec emd_maintenance.gather_sysman_stats_job(p_gather_all=>’YES’);
========== ========== ========== ========== ========== ========== ==========
========== ========== ========== ========== ========== ========== ==========
== Target system tuning ==
========== ========== ========== ========== ========== ========== ==========
– Setting the PING grace period to (90) (60->90)
– Set the parameter oracle.sysman.core.omsAgentComm.ping.heartbeatPingRecorderThreads to 3
$ emctl set property -module emoms -name oracle.sysman.core.omsAgentComm.ping.heartbeatPingRecorderThreads -value 3
========== ========== ========== ========== ========== ========== ==========
not spooling currently